Support a New Data Model
Source:vignettes/customize_support_new_data_model.Rmd
customize_support_new_data_model.RmdOverview
Currently, ReviewR is capable of displaying patient information from databases that conform to the MIMIC-III and OMOP data models. However, we recognize that clinical data can be stored in a variety of different formats. Accordingly, ReviewR can be extended to display patient data for additional data models. This vignette is organized into two main sections focused on the mechanics of data model support in ReviewR and how to add support for new data models:
- ReviewR Data Model Support - Describes how different data models are supported by ReviewR
- Adding Support for a New Data Model - How to add support for a new data model to ReviewR
ReviewR Data Model Support
A data model defines the tables and fields that are contained within a database. These definitions are typically described in a schema file, which provides a full listing of the tables and fields contained within a database. ReviewR uses the definitions stored in a data model schema file to select an appropriate set of internal ReviewR functions to display the patient information that is presented on the “Chart Review” tab. In ReviewR, these functions are referred to as “table functions,” as they are responsible for querying, formatting, downloading and ultimately displaying patient information from the tables in your connected clinical database. These special functions are dynamically selected based on the data model that is detected when connecting.
In order for ReviewR to display patient data stored in other data models, support must be added. Developing support for additional data models requires some understanding of two ReviewR’s mechanics:
-
Data Model Detection: ReviewR
must be able to detect the patient data model of the connected database.
- A schema file is required to add support for custom data models. Schema files must be CSV formatted and contain two columns: table and field. These columns must contain a pairwise combination of every table and field in the target data model.
-
Data Model Display: ReviewR
requires a set of “table functions” specific to a detected data model to
define every aspect of how the patient data is displayed.
- Table functions must follow the table function naming convention.
These components will be discussed in the sections that follow.
Data Model Detection
When a database connection is established, ReviewR will use the connection information supplied from the database connection module to interrogate the connected database and attempt to determine the data model and data model version. ReviewR accomplishes this task by discovering the table and field names of the connected database and comparing them with data model specifications that have been built into the ReviewR package. The built in data model that has the most matching table/field combinations to the connected database will be identified as the currently connected data model.
If data model detection is successful, ReviewR will select the appropriate table functions that have been built into the package that correspond to the detected data model to display the information stored in the database tables. Additionally, ReviewR calculates an internal variable, called table_map which will be used to map the table and field combinations in the connected database back to corresponding table and fields of the detected data model specification. This allows for case insensitive matching between between the data model specification and the connected database.
If however, ReviewR fails to identify enough table and field matches to data models with existing ReviewR support, data model detection will fail, and ReviewR will be unable to display patient information from your connected database. An error message will be presented upon connection, notifying you of this.
To see a list of currently supported database specifications in ReviewR, run:
library(ReviewR)
ReviewR::supported_data_models
#> # A tibble: 12 × 4
#> # Groups: file_path, data_model, model_version [12]
#> data_model model_version data file_path
#> <chr> <chr> <list> <chr>
#> 1 mimic3 "v1.4" <tibble [332 × 8]> data-raw/data_models/mimic3_v1.4…
#> 2 mimic3 "" <tibble [333 × 8]> data-raw/data_models/mimic3.csv
#> 3 omop "v4" <tibble [49 × 8]> data-raw/data_models/omop_v4.csv
#> 4 omop "v5.0.1" <tibble [328 × 8]> data-raw/data_models/omop_v5.0.1…
#> 5 omop "v5.1.0" <tibble [339 × 8]> data-raw/data_models/omop_v5.1.0…
#> 6 omop "v5.1.1" <tibble [339 × 8]> data-raw/data_models/omop_v5.1.1…
#> 7 omop "v5.2" <tibble [365 × 8]> data-raw/data_models/omop_v5.2_b…
#> 8 omop "v5.2.0" <tibble [334 × 8]> data-raw/data_models/omop_v5.2.0…
#> 9 omop "v5.2.2" <tibble [363 × 8]> data-raw/data_models/omop_v5.2.2…
#> 10 omop "v5.3.0" <tibble [407 × 8]> data-raw/data_models/omop_v5.3.0…
#> 11 omop "v5.3.1" <tibble [407 × 8]> data-raw/data_models/omop_v5.3.1…
#> 12 omop "v6.0" <tibble [427 × 8]> data-raw/data_models/omop_v6.0.c…A data frame with 4 columns will be returned:
- data_model: The data model name
- model_version: The data model version
- data: A nested data frame with the schema of the data model itself
- This schema information comes from CSV files that may be built into the ReviewR package
- file_path: The file path* of the data source
*Note: The data-raw file path is only available when forking the ReviewR repository from GitHub.
Schema Files
Data model specifications are provided by schema files which are
comma separated values (CSV) formatted files that contain at least two
columns, table and field, which identify every
field for every table in the data model. If you are using a common data
model, they may be available from the consortium that define the data
model standards. If obtained from a developer, these files may include
additional information beyond the required table and field designations.
These files may still be used, but additional descriptors will be
ignored. The schema file for the OMOP CDM v5.3.0 is provided as an
example:
Table 1: OMOP v5.3.0 Schema obtained from OHDSI
Files such as these can be built into the ReviewR package, so that it may identify additional data models and display the corresponding patient information.
Data Model Display
Displaying patient data from other data models is made possible by developing “table functions” which are incorporated into the ReviewR package namespace. Functions provide a convenient way to code table representations, as they can accept data model and connection info from ReviewR as variables. Additionally all of the necessary code required to display your data model tables exists in one place easily modifiable place. Writing functions is hard! Writing good functions takes a lot of practice. Do not use the ReviewR code base as a guide for good function writing. Instead, take a look at https://r4ds.had.co.nz/functions.html for information on how to write good functions.
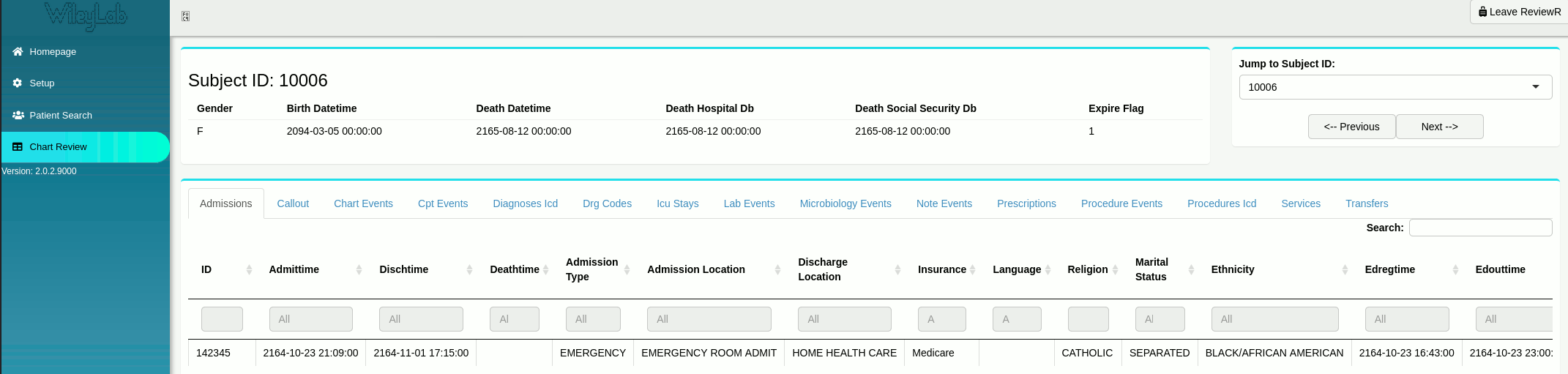
Patient information tabsets on the “Chart Review” tab of ReviewR are generated by table functions.
Once ReviewR has determined data model and version of the user database, it will search for appropriately named functions that can be used to download and display the information contained within the connected data model. These table functions must be named according to a specific naming convention.
Two convenience functions have been included with ReviewR to assist
in developing the required table functions for your data model:
user_table and user_field. These functions
allow for table functions to be coded by requesting the desired table
name from the schema file. ReviewR then performs case insensitive
matching to the appropriate table/field in the user’s connected data
using the table_map variable as discussed previously.
When developing table functions for ReviewR, there are two different types of table functions that must be considered. The first, is the table function that will be responsible for generating the information on the “Patient Search” tab, which contains demographic information for every patient in the database. In ReviewR terminology, this is referred to as the “All Patients” 1 table.
For example, in the OMOP data model, demographic information is contained within the “person” table. An “All Patients” table function that could be used to display this information on the “Patient Search” tab could take the following form:
omop_table_all_patients <- function(table_map, db_connection) {
user_table(table_map, db_connection, 'person') %>%
mutate(ID = user_field(table_map, 'person', 'person_id')) %>%
collect()
}The above will retrieve the “person” table in the user connected
database, using the table_map and db_connection
variables to locate the correct table and securely access the database,
respectively. These variables are supplied by ReviewR and should be used
as arguments to this function. Additionally, the column containing your
data model’s subject id (record id, patient id, person id, Medical
Record Number, etc.) must be renamed to ‘ID’. In the OMOP data model,
this field is coded as ‘person_id’. Using the user_field
function, we can locate the field of interest in our connected data by
supplying the function with: the table_map variable, the table
we know the field to exist in, and the field we’d like to retrieve. We
can then transform this column name to ID using the mutate
function. This informs ReviewR that when a user selects this ID column,
all information on the “Chart Review” Tab will need to be filtered to
the identifier selected from this column.
The second type of table function will be responsible for displaying the clinical data as depicted on the “Chart Review” tab. In most clinical data models, any given table will contain a particular type of patient information for every patient in the data set. Thus, information in these tables must be filtered down to a singular subject, usually by a numeric identifier. In addition to the table_map and db_connection variables, these “Subject Specific” 2 table functions must accept an additional subject_id argument:
omop_table_condition_occurrence <- function(table_map, db_connection, subject_id) {
user_table(table_map, db_connection, 'person') %>%
filter(ID == subject_id) %>%
collect()
}This function will retrieve the “condition occurrence” table from the connected database, filtered to contain only the conditions that pertain to the selected subject.
Table Function Naming Convention
Table functions have a standard naming convention, which allows for
them to be associated with the currently detected data model. Functions
used to render patient tables must have the following format:
{data-model-name}_table_{table-name}. They start with the
name of the data model (no spaces, dashes, or underscores are allowed,
though CamelCase is acceptable) followed by “_table” and then end with
the name of the table you would like to display (long table
names may include underscores). This last bit of the function name will
become the label of the tabset on the “Chart Review” tab in ReviewR.
When developing table functions for a particular data model, there must
be exactly 1 function that codes for the “All Patients” table (function
name ending in ’_all_patients’) and any number of additional “Subject
Specific” table functions.
As an example, say you would like to add support for the PCORnet data
model to ReviewR. After you have added a schema file for the PCORnet
version that you would like to support, you will have to create an “all
patients” table function and 1 or more “subject specific” table
functions. In PCORnet, patient demographic information is stored in the
“DEMOGRAPHICS” table, but this is irrelevant for the function
name that will ultimately connect to this table. The appropriate
name for the “all patients” table function would be:
PCORnet_table_all_patients. This function will contain code
that connects to the “DEMOGRAPHICS” table, and will be used to display
the patient list on the “Patient Search” tab of ReviewR.
Additional “subject specific” table functions will need to be created
to display information on the “Chart Review” tab of ReviewR. For
example, an appropriate name for the “ENCOUNTER” table function would
be: PCORnet_table_ENCOUNTER. This would add a tabset to the
“Chart Review” tab of ReviewR with the label “Encounter.”
This naming convention ensures that when ReviewR detects that a
PCORnet database is connected, all functions beginning with
PCORnet_table_ will be available to display the patient
information. Once table functions have been created for a data model,
all functions that have been developed will displayed as tabs in the
Chart Review section of ReviewR when the new data model is detected.
Adding Support for a New Data Model
ReviewR has been developed as a package utilizing the golem framework. Essentially, this means that the Shiny application is organized in such a way that all major application features are provided by functions. These functions are disambiguated from other functions in your R package library because they exported with the ReviewR package’s namespace. This also helps ReviewR to access the functionality of other packages through namespace imports.
The advantages to this approach include ease of distribution, providing inline application documentation, and providing a reasonable expectation of installation/deployment success across different operating systems and server environments. To learn more about package namespaces, please see: https://r-pkgs.org/namespace.html
This does however introduce some additional caveats to the
development process. The main caveat to be aware of when developing for
ReviewR is that any changes made to ReviewR’s code will not immediately
be reflected the next time the application is launched. The reasons for
this are fairly technical, but the root of the issue is that new changes
must be explicitly added to the package namespace. Golem provides a
function that will both update any necessary documentation and load all
of the development changes since the last save into the active R
session, so that new changes to the code can be tested without having to
rebuild and install each time a change is made. After making code
modifications, simply run golem::document_and_reload() to
make the new changes available the next time the application is
launched.
For additional information about developing an R Shiny application
with golem, please see: https://engineering-shiny.org/index.html
Getting Started
First ensure you have access to the latest development tools and file structure of the ReviewR package, fork ReviewR from GitHub. For simplicity, the home directory is specified as a destination directory:
# install.packages('usethis')
usethis::create_from_github(repo_spec = 'thewileylab/ReviewR', destdir = '~/')Please see this guide if you have trouble connecting RStudio with Git. It is also possible to fork this repository directly from GitHub if all else fails.
IMPORTANT: If you think you would like to contribute data model support to the ReviewR project, start a new branch to hold your development work. However, if these changes are only for your own use or for a custom data model that does not have widespread use cases, feel free to perform your development work using the default branch.
Navigate to the forked repository and open the
ReviewR.Rproj file. This will open the project in RStudio.
Finally, using the devtools package run:
# install.packages('devtools')
devtools::load_all()You are now ready to begin the developing support for a new data model.
Required Information
To begin, either obtain or create a schema file for the data model that you would like to support. As stated previously, this file must be CSV formatted and contain two columns labeled table and field. The contents of this file will be a pairwise combination of every table/field in your target data model.
How to Add a New Data Model
A convenience function has been built into ReviewR to assist with the
task of adding support for additional data models:
dev_add_data_model().
This function is accepts a single argument, the path to a schema file on your local machine. This function is intended for development purposes, and as such, it must be run by appending 3 colons (:::) after the package name, as in the following example:
ReviewR:::dev_add_data_model(csv = 'path/to/schema/file.csv')When run, this function will process the information stored in the specified schema file and prompt you for some basic information pertaining to the data model that you are attempting to add support for. The first prompt that you will encounter is to identify which table contains a listing of all patients. A listing of every table in the schema file will be presented in the viewer pane of RStudio for you to browse and locate the table containing the requested information. Enter the number that corresponds to the correct table in the console and press return to proceed.
Next, you will be asked which field contains the patient identifier in the schema file. A listing of distinct fields will be presented in the viewer pane. Locate the desired field and enter its numeric representation into the console, followed by return.
At this point, the function has all of the information that it needs to add very basic support for your data model to ReviewR. The schema file will automatically be added to the list of supported data models and a R file containing pre populated table functions will open with some very basic table representations coded. At this point, you may want to customize the representation for each table to your liking.
If your data model is simple, and each table stands on its own, ie. it does not contain relational information, you are done! Save your changes to the table function file and run:
golem::document_and_reload()To incorporate your new data model support into ReviewR.
If however your data model is relational, such as with OMOP (and
others) you may have additional work to do. It is important to note that
the dev_add_data_model function will create a skeleton
function for every table contained within your schema CSV file.
This is often not appropriate for relational databases, as certain
tables do not contain actual patient information, but rather hold
information about data stored in other tables.
In OMOP, this is seen most often with the concept table. The concept
table, on its own is likely not a table you’d like to display in
ReviewR, and would need to be manually removed from the resulting table
functions file as generated by dev_add_data_model. However,
almost every other table in the OMOP data model will require a join with
the concept table in order to access the patient information. Therefore,
table functions will need to be modified to make the appropriate joins
on the concept table. For example:
omop_table_all_patients <- function(table_map, db_connection) {
user_table(table_map, db_connection, 'person') %>%
mutate(ID = user_field(table_map, 'person', 'person_id')) %>%
left_join(user_table(table_map, db_connection, 'person'),
by=setNames(user_field(table_map, 'person', 'gender_concept_id'), user_field(table_map, 'concept', 'concept_id'))
) %>%
collect()
}The above will add the human readable representation of the subjects gender to the ‘person’ table, rather than the numeric concept that is stored in the “person” table. For additional information on the OMOP data model, please consult the OHDSI OMOP website.
When developing, it is important to be aware of these relationships so that appropriate joins can be made to correctly the display the information properly to the user. Tables which contain relational information need not be displayed on the Chart Review Tab, and the table function skeletons created by the dev function may safely be removed.
Developing/Testing
When making modifications to the template provided by
dev_add_data_model, feel free to select(),
filter(), mutate(), or otherwise modify the
appearance of the patient data such that it displays how you want it to
look on the Chart Review tab. The dplyr package has been
declared as an import in the table function skeleton, so that the many
dplyr manipulations may be included in your development.
Please leave the collect() part of the dplyr chain that has
been added, as data needs to be downloaded to ReviewR in order to be
displayed.
When you are ready to test these table functions within ReviewR, run:
golem::document_and_reload()
ReviewR::run_app()This will incorporate your newly developed functions into the active
R Session and launch the application so that you can connect to your
database and view your new data model within ReviewR. Remember, after
any change to the table functions you will have to run
golem::document_and_reload()
Finishing up
Once you are satisfied with your table functions and have sufficiently tested their functionality, run:
devtools::install()This will install a new, custom version of the ReviewR package with your newly incorporated data model and supporting table functions.
If you have developed support for an additional data model using this vignette, and would like to contribute to the ReviewR project, we ask that you please consider submitting your work as a pull request. Please follow this excellent pull request guide if you would like to contribute your modifications to the ReviewR package: